JUGANDO CON LA PSICOACÚSTICA
Memoria acústica
Uno de los campos donde más me he divertido en mis etapas de formación e investigación es, sin duda alguna, en la psicoacústica. Debido a mi naturaleza basada en el entendimiento y en el intentar descomponer el porqué de las cosas, siempre que iba a un concierto y este sonaba mal me resistía a pensar que era por culpa del técnico. A veces, cuando tenía la suerte de conocerlo, sabía de antemano que era casi imposible que esa persona hiciera mal su trabajo, pero había algo en su mezcla que hacía que prefiriera irme a casa en vez de disfrutar del concierto. ¿Cómo podía ser? Lo fácil (y habitual) es dirimir la discusión a la mala praxis del técnico del momento, pero empecé a preguntarme que quizá era yo quien escuchaba mal las cosas. En definitivas cuentas, el resto del público seguía disfrutando del concierto y no parecía estar enojado por esa misma mezcla que a mi me parecía casi horrorosa. ¿Estaría sordo? ¿Qué estaba pasando?
Empiezo esta serie de artículos que se alejan de las vicisitudes técnicas y nos acercan a laimperfección del ser humano. Basados en los conceptos básicos de la psicoacústica, nos ayudarán a resolver algunos de los problemas más habituales a los que nos encontramos en nuestro trabajo y que no hemos sido capaces de resolver. A todo ello, sigo esperando respuesta a uno de los dilemas que publiqué hace ya algunas semanas: ¿cómo es que el ser humano, con sólo dos orejas, es capaz de reconocer si un sonido viene del frente o de detrás?
Escucha más nuestro cerebro que nuestros oídos
Los más veteranos sin duda reconocerán esta habitual anécdota. ¿Os acordáis cuando los teléfonos eran analógicos, a pulsos, y no tenían pantallita alguna? Nos llamaban a casa y el que más cerca estaba del aparato lo recogía con un “dígame” universal. Luego, nuestro cerebro empezaba su catarsis: a partir del “hola” siguiente debía resolver a velocidad de vértigo quién se encontraba al otro lado del aparato. En ambientes familiares nadie se presentaba, como dando por hecho que todo el mundo se reconoce, pero no es así.
Los teléfonos analógicos (e incluso los digitales de hoy en día) utilizan un método de compresión de datos muy eficiente: reducen el ancho de banda en la respuesta de frecuencia para así enviar menos datos. La voz tiene su dominante en frecuencia entre los 2 y 6 kHz, por lo que todo lo que está por debajo y encima es futil si lo que queremos es centrarnos en el mensaje. Bueno, lo es menos para un dato: son esos armónicos superiores e inferiores los que determinan el timbre de cada uno de nosotros. Pero el teléfono los elimina, los dilapida. Así, cuando nos llamaban y el interlocutor nos descubría empezaba a preguntarnos cómo estábamos, si estaban papá o mamá y que se pusieran al interfono… ¡Qué rabia! El del otro lado sabía quien era, pero yo era incapaz de saberlo. Pero de pronto lo reconocías: ¡era el tío José! Y en ese momento, esa voz distante, capada y fuera de lugar, parecía verdaderamente como si fuera emitida por alguien que realmente estaba a tu lado, hablándote a dos centímetros de tu cabeza. Bienvenida psicoacústica.
En el momento exacto que nuestro cerebro sabe determinar a quién pertenece esa voz, recurre a los recuerdos almacenados para reconstruir todo aquello que no nos llega. A tiempo real, añade todos esos matices que ni tan siquiera el teléfono es capaz de ofrecer, porque los ha eliminado, ofreciéndonos esa sensación de que, realmente, nuestro interlocutor está a nuestro lado.

Bose, entre otras cosas, fue reconocida por su serie de altavoces Acoustimass. Se basaban en este mismo principio. Fue capaz de ofrecer un sonido contundente y ‘espectacular’ utilizando unos minicubos y un pequeño subwoofer. ¡Sonaba de escándalo! De hecho, las primeras demostraciones de estos sistemas se hacían con trampa: permitían a los espectadores escuchar una pareja de altavoces de tipo columna, de algo más de metro de altura; y cuando estaban convencidos de la calidad de ese equipo, alguien sacaba de dentro de esa caja inherte esos dos minicubos pequeños y dejaba asombrados a los asistentes. Yo compré una pareja de ellos. Los tuve en mi casa durante unos pocos meses: sonaban bien, pero me fatigaban. Bose no inventó la capacidad de un altavoz de baja pulgada para reproducir perfectamente todas las frecuencias del espectro sonoro, sino que jugó hábilmente con nuevas ecualizaciones muy drásticas y otros elementos para conseguir una sensación de respuesta absoluta, pero que dejaba en manos del cerebro la necesidad de reconstruir todos esos sonidos que eran imposibles de reproducir físicamente. Así, tras un largo rato de escucha mi cabeza casi explotaba, cansada de estar recalculando frecuencias y generando a partir de recuerdos sonidos no emitidos. Lo mismo ocurre con los MP3.
A ver con qué pruebas el equipo de sonido
Linn Products es un pequeño, extraño pero prestigioso fabricante de productos de alta fidelidad. Los conocí hará una decena de años y me sorprendieron cuando los visitaba para realizar audiciones de sus equipos de música: nunca me permitieron utilizar mis propios CDs. Con el tiempo no sólo les doy la razón, sino que ahora entiendo el porqué. Estaban tan orgullosos de sus equipos que podían permitirse este arriesgado experimento.

Basándose en la anterior premisa, sabían que nuestro cerebro sería capaz de reconstruir infinidad de detalles sonoros incluso si las cajas no lo reproducían. Así las cosas, te incitaban a escuchar sus equipos con músicas que no conocieras, justamente, para evitar que lo que no escuchabas fuera reconstruido por tu cerebro. Cuando pruebas un equipo de sonido con una música que conoces de sobra es probable (por no decir seguro) que tu cerebro te engañe, pues además tenemos poco control sobre él. Te hará escuchar graves profundos y controlados donde no hay más que rebomborio acústico o, incluso, añadir colas de reverb donde no las hay. Si en cambio pruebas un equipo con un pasaje musical que no conozcas demasiado estarás obligado a escuchar lo que escuchas: tu cerebro no sabrá si ahí hay una línea de bajo definida, un detalle en agudos a apreciar o si existe inteligibilidad de la palabra. Si escuchas una canción en tu idioma materno es fácil que “reconozcas” palabras enunciadas donde hay barullo; en cambio, si reduces la escucha a un idioma que conozcas pero no sea tu habitual, el simple hecho de reconocer fácilmente palabras hará que estés de acuerdo con la reproducción, justamente, del espectro más crítico para el ser humano y la palabra: entre 2 y 6 kHz.
Aún así, la memoria auditiva o acústica es muy volátil si no está fijada en el recuerdo. El perfil de la voz del tío José permanecerá casi intacto de por vida, pero un ajuste determinado de un compresor para un bombo que nos suene bien puede volatilizarse en cuestión de un par de segundos, mucho antes de poder ajustar de nuevo el compresor. Por ello, muchos fabricantes de software incluyen la opción A-B que nos permite hacer esta comparación rápidamente. Y tenemos que hacerlo ipso-facto: esperar apenas 1 segundo entre dos sonidos a comparar nos inducirá totalmente al engaño.
Antes de terminar este artículo, el primero de una serie (si me lo permitís), recordar otra anécdota tremendamente común: el músico que pide que le subas un poco la guitarra y que de pronto te felicita por ello cuando tu ni siquiera has tocado potenciómetro alguno. Lo mismo nos ocurre a nosotros (como técnicos): la cantidad de ajustes que realizamos al vuelo durante una actuación que no ejercen función alguna pero que, engañados por nuestro cerebro, creemos que son factibles. Para solucionar esto saquemos provecho de lo que hemos dicho justo ahora: si nuestra memoria acústica es volátil al segundo, entre un cambio y la comparación del siguiente hagamos un mini-reset de nuestra percepción sonora. ¿Cómo? Escuchamos el bombo, lo modificamos y acto seguido centramos nuestra atención en la caja… para luego volver a escuchar el bombo, esta vez limpio de recuerdos, para oir lo que realmente suena.
Fletcher-Munson
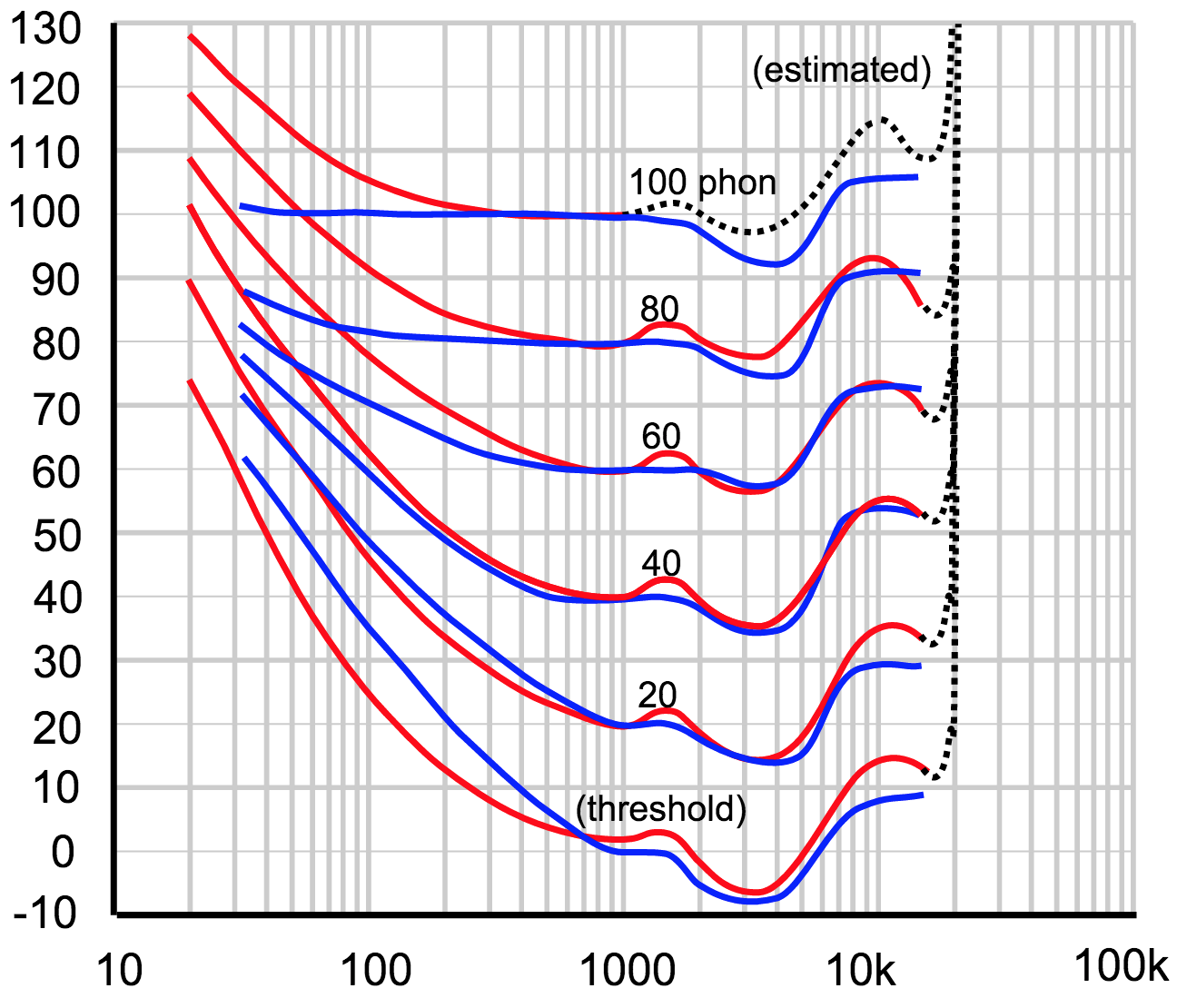
Fue en 1933 que dos trabajadores de Bell Labs, Harvey Fletcher y Wilden A. Munson, introdujeron por primera vez el concepto de loudness, asentando que, definitivamente, nuestro oído no tenía una respuesta lineal —era incapaz de escuchar todas las frecuencias por igual—. Nuestro oído está diseñado específica y maravillosamente para la inteligibilidad de la comunicación oral, es decir, para tener una respuesta perfecta entre 2 y 6 kHz. Pero tal y como reflejan las famosas curvas isofónicas o de Fletcher-Munson, nos cuesta escuchar los sonidos cuya frecuencia esté fuera de ese alcance, sobre todo las del espectro inferior (y, curiosamente, el pico de 8-9 kHz). No sólo eso, sino que la respuesta es distinta en función del nivel de presión sonora.
Hasta hace pocos años era fácil ver una opción en los equipos de sonido de alta fidelidad domésticos: loudness. Un pequeño conmutador que aumentaba graves y agudos cuando nos decidíamos a reproducir pasajes sonoros a bajos niveles de volumen; si lo manteníamos encendido a niveles de volumen alto la descompensación era evidente (otra cosa es que nos gustase más).
Lo importante de las curvas isofónicas no es sólo ver que no tenemos una respuesta lineal, sino que, además, esta respuesta varía en función del nivel de presión sonora: a menos volumen, menos percepción tenemos de las bandas graves y agudas manteniéndose las medias, una relación que no es para nada lineal cuando modificamos el volumen al alza. ¿Qué quiere decir esto a nivel práctico? Que cuando tenemos una mezcla que nos gusta a un nivel de presión dado, si nos decidimos a subir o bajar el nivel del máster todo se nos descompensará: tenemos que estar preparados.
En realidad, nuestra respuesta es más plana (aunque nunca del todo) cuando el nivel de presión sonora es muy alto. Nuestro oído responde similar a un compresor-limitador en este sentido. Esto indica que si haces una prueba de sonido a un nivel de presión alto (digamos algo muy alto), obtendrás una mezcla compensada a lo que podríamos llamar un estándar lineal. Esa misma mezcla reducida en volumen pecará de falta de agudos y, sobretodo, graves. Hacerlo al revés implica que una mezcla compensada a un nivel determinado de volumen, una vez aumentas la salida del máster, hará que graves y agudos sean más perceptibles. ¿Qué preferimos? ¿Aumentar o disminuir la respuesta subjectiva de las frecuencias?
Para responder lo anterior debemos reconocer cómo responde psicológicamente el ser humano a un exceso de graves y a un exceso de agudos. Curiosamente, un exceso de graves no nos produce el “dolor” que sí notamos en un exceso de agudos. Casi al contrario: las mezclas más efectistas las conseguimos cuando los graves están algo por encima. Pero todos sabemos reconocer que unos agudos demasiado evidentes nos producen entre desagrado y dolor (de hecho suele disparar una “alarma” de peligro). Conociendo esto y teniendo en mente el ejemplo anterior, nuestro objetivo principal sería controlar con absoluta precisión cualquier aumento no deseado de la banda alta de frecuencias (agudos). Justamente por ello, cuando hago mis pruebas de sonido reparo la misma trabajando a un alto nivel de presión sonora, lo que me indicará no sólo la respuesta del equipo (que también es tremendamente importante), sino que en caso de necesidad, al subir de nivel toda la mezcla evitaré esos sonidos estridentes tan poco deseados. A la vez consigo poner en alerta a los productores del evento que, normalmente, corren a control a decirme que me estoy pasando… Háblales ahora de las curvas Fletcher-Munson, de la respuesta psicoacústica y de lo limitado que está el equipo. Pero este es otro tema...
¿Existe alguna manera de compensar las diferencias de percepción en función del nivel de presión sonora? Lo ideal sería un sistema que en función de ese nivel aplicase una corrección, llamémosla, ‘Fletcher-Munson invertida’. El problema de esta solución es que depende del ser humano y, por tanto, de la posición absoluta de cada persona respecto del recinto acústico principal: el público más cerca del escenario (y por ende de la PA) recibirá más graves y agudos —chillones— que el público que esté detrás de la mesa de control. Si compensamos los agudos para los fans, olvidaremos matices importantes en esa banda para la gente que esté a 10 o 20 m de distancia. Supone un problema muy complejo.
Pero sí podemos insertar en la mezcla un compresor multibanda que compense las diferencias de percepción auditiva humana en función del nivel de salida, un compresor de recorrido algorítmico y multibanda que aumente graves y agudos de manera diferenciada según la salida, a la vez que reduce ese aumento (e incluso comprima la banda media) cuando el nivel de salida se acerca al límite. La idea es tremendamente atractiva, pero es complicadísimo de ajustar. Aún así, probadlo, porque la solución es tremendamente más atractiva que la inclusión de un compresor de banda total (algo mucho más habitual hoy en día), aunque pueden complementarse perfectamente.
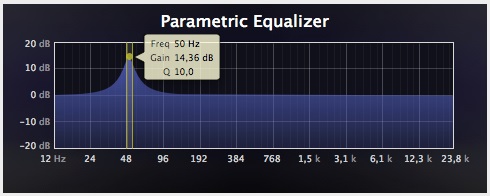
No todas las consolas disponen de serie de plug-ins de compresión multibanda o no todos tenemos la posibilidad de poder insertar un compresor tipo C4 o C6 de Waves o un MC2000 de McDSP. Pero sí es mucho más fácil, a malas, realizar este ajuste de manera “manual”: insertando en la salida máster un ecualizador paramétrico. Cada vez que modifiquemos el volumen de PA restituiremos las frecuencias que nuestro oído percibe mejor o peor. ¿Con qué ajustes? Echad un vistazo a las curvas isofónicas.
Fijaos bien en las curvas Fletcher-Munson y daos cuenta de las diferencias que existen a niveles de presión dados: pueden ser de hasta 30 dB o más de intensidad. La mejor de las mezclas es aquella que, además de un sonido agradable, ofrece de manera audible detalles armónicos que enriquecen la misma, y eso a veces se consigue con un aumento de 20-30 dB en el espectro superior de la respuesta en frecuencia; aunque, como hemos visto, un exceso en ese punto puede suponer todo lo contrario: un dolor molesto que puede reducir a cenizas nuestro trabajo.
El oído humano y el cerebro tienen sus herramientas ante los desastres de los técnicos. Todos conocemos a alguien a quien los agudos les molestan tremendamente y podríamos concluir que esta persona no sólo tiene el sistema de “alarma” con un umbral muy bajo sino que, además, su cerebro no permite aplicar ese especie de filtro anti-agudos que otros sí tienen. ¿Recordáis cómo empezaba el artículo anterior sobre psicoacústica? Me quejaba de que el sonido de mi compañero técnico era estridente, pero me sorprendía de la capacidad del público en soportarlo. De hecho, si la distorsión (entendiéndola como lo que significa: la reproducción no fiel ni controlada) de los agudos se realiza de manera progresiva, el cerebro compensa la adición con una especie de substracción subjetiva que permite, poco a poco, mantener a raya el nivel de “alarma”. En cambio, para unos oídos frescos la “alarma” salta a la primera.
Volvemos al final del primer artículo: la necesidad del técnico de poder “resetear” de vez en cuando su cerebro para recuperar los umbrales de referencia ‘normales’. Un sistema, cutre pero eficaz, es tan sencillo como taponarse los oídos con los dedos unos 5-10 segundos, pensando, si puedes, en cualquier otra cosa que no sea música. Ya comenté que nuestro cerebro es potente, pero curiosamente no tiene una memoria acústica de corto tiempo. Al volver a escuchar nos será fácil, durante unos pocos segundos, analizar lo que realmente está ocurriendo y, evidentemente, tener la información precisa para corregirlo.
Frecuencias.

Light you up haciendo pruebas de sonido
A todos nos ha ocurrido y nos sigue ocurriendo: empiezas las pruebas de sonido con el bombo y, tras 5 minutos de ensayo/error, estás convencido de que ese sonido grave, contundente y de ataque preciso es perfecto. Sigues con la caja, toms, ambientes, etc. Le dices al batería que lo toque todo, como si le fuera la vida, y disfrutas, tras unos pequeños ajustes de la mezcla, de esa batería portentosa y agradecida. Sigues con el bajo, los teclados, las guitarras y las voces. Llegas a un punto, deseado, en que casi vas a pedirles a todos los músicos que toquen un tema, y estás entre la prueba final y ese momento en que quisieras chillar a todo el mundo: “¡esto es lo que soy capaz de hacer!”.
Pero ahí te la pegas. Esos sonidos casi perfectos que has conseguido desaparecen de golpe, ycuando la banda toca junta nada suena como esperabas. El problema no es psicoacústico, sino técnico: has probado sin mantener un rango dinámico adecuado, ejecutando los sonidos a su máximo sin pensar que sólo eran una parte de un todo. Bajas todos los volúmenes, rehaces las dinámicas, la compresión… y aunque eres capaz de sonsacar otra buena mezcla, para nada se acerca a ese ideal que te habías construido poco a poco durante la primera ronda de pruebas.
¿Os acordáis de ese curioso efecto de nuestro cerebro que nos permite “escuchar” rangos enteros cuando en realidad no lo estamos escuchando? ¿Cuando al saber que era el tío José quien nos llamaba por teléfono nos parecía, ahora sí, que estaba hablándonos como si estuviera a un palmo de nosotros? Pues aprovechemos este “(d)efecto” a nuestro favor ante estas situaciones.
El reto no es conseguir el máximo de presión sonora, sino poder ganar o simplemente mantener dinámica ante situaciones complicadas (algo que, sin duda alguna, es el éxito de una buena mezcla) a cambio de no machacar la presión sonora que, dicho sea de paso, suele ser la “solución” para una gran mayoría de técnicos.
Lo peor que le puede suceder a un grupo de versiones es no sonar como sus ídolos. El espectador tiene clara una referencia sonora exacta que habrá escuchado mil y una veces y esperará que el sonido esté lo más cerca posible. En esta situación, la banda, el técnico y el público tienen claros los objetivos sonoros y conseguirlos es, en una buena parte de casos, realmente fácil. Ahí donde no llega el virtuosismo del técnico, del músico o del cantante, llega el recuerdo mental de los sonidos originales, que en cierta manera ayudan a que, de vez en cuando, cierres los ojos y veas tu banda favorita en el escenario, y no esos individuos de los que ni conoces su nombre real. Al contrario, cualquier banda desconocida puede querer un sonido determinado y conseguirlo, pero la falta de referentes sonoros ayuda cualquier impedimento a la hora de no conseguirlos: el espectador no sabrá con qué compararlo. Por lo tanto, sí o sí, recurrirá a “estándares”, tan sencillos como reconocer que hay un bombo, un bajo, unas eléctricas y unas voces con, quizá, un mensaje interesante para escuchar.
Dejando de lado la inteligibilidad de la palabra, cuando el equipo no es capaz de facilitar las cosas al técnico o, incluso, los instrumentos musicales (y su maridaje con los micrófonos, previos, mesa, etc., o incluso músicos) no alcanzan lo deseado, podemos recurrir a este curioso efecto de memoria sonora mental para arañar potencia y respuesta a nuestra mezcla. El ejemplo más claro lo tenemos con el bombo y el bajo. Normalmente, estos dos elementos suelen ir a la vez: el bombo otorga el “golpe” mientras que el bajo ofrece la “nota”. Pero ambos hacen una demanda energética en el espectro grave demasiado contundente, lo que nos puede llevar al desastre. ¿Cómo podemos reducir la demanda energética —y por ende de presión sonora— para mejorar nuestra mezcla dinámica y, a la vez, no eliminar nada?
Hoy en día es fácil encontrarte con compresores con sidechain. Esta función permite el control de la compresión tomando como referencia un elemento externo. Por ejemplo, podemos aplicar al bombo una compresión superior (además de la compresión ‘normal’ que deseemos para este instrumento) en función del nivel de señal del bajo: cuando el bajo esté sonando, comprimiremos todavía más el bombo. Aplicando un tiempo de ataque relativamente largo a esta configuración, el espectador escuchará perfectamente el ataque del bombo, pero luego éste desaparecerá rápidamente a favor de una “cola” de grave con nota, la del bajo. A su vez, si el bajo silencia su nota por lo que sea, la cola del bombo que tengamos preparada —si aún está viva— podrá volver en escena (lo que implica un tiempo de release relativamente corto). Nuestro cerebro tendrá la información suficiente para entender que hay un bombo potente y grave, y aunque desaparezca durante un momento, tendrá la información suficiente como para “restituir” de manera silenciosa lo que realmente no escuchamos.
Sabemos, gracias a Fletcher-Munson, que la respuesta en frecuencia del oído humano está diseñada para la inteligibilidad de la palabra. Ante limitaciones del equipo, lo suyo es mantener “clara” la zona entre 2 y 6 kHz para permitir que el mensaje sea propagado con facilidad. En caso de complicaciones, nos queda reducir el volumen o presencia del resto de elementos que puedan ocupar esa misma zona. Pero podemos probar de nuevo esta solución. Por ejemplo, un hihat de pulgada grande puede molestar la inteligibilidad de la palabra. Podemos hacerle un hueco importante en la zona de 2-6 kHz y “compensar” la ecualización con un agudo más inciso, algo bien comprimido (lo que nos evitaría un sonido estridente). No se escuchará como debería, pero sí ofrecerá información suficiente como para decirle al cerebro del espectador que en realidad ese hihat debería sonar más fuerte en la zona de 2-6 kHz, cosa que seguramente hará, sin que para ello debamos sacrificar la palabra. Tenemos que pensar que la atención del espectador se centrará en otros sonidos, no en la mayoría de ello. Saber discriminar qué es importante de lo que no y tener la habilidad de “mover” y/o engañar el cerebro de quien escucha para mejorar el global de nuestro trabajo.
¿Cuáles son los límites? Ya deberíais saber la respuesta: la fatiga auditiva. Si demandamos mucho a nuestro cerebro en este sentido, a medio plazo empezará a cansarse, fatigarse. Si a eso le añadimos que no estará sentado cómodamente en su sofá y que, seguramente, ya se habrá tomado un par de cervezas, la fatiga no sólo llegará antes, sino que fácilmente ayudará al espectador a desconectarse del concierto. No hay fórmula exacta ni valor científico alguno que defina un rango de “engaño mental acústico”, por lo que lo suyo es el sentido común (y, cómo no, la experiencia).
Muchos técnicos de sonido de PA de renombre utilizan asiduamente estas técnicas, aunque la mayoría de veces no son conscientes de ello. Por eso, muchas bandas noveles o que todavía no consiguen llenar grandes espacios (y, por ende, no son tan reconocidas), suelen contratar este tipo de técnicos en cuanto son capaces de conseguir los mejores resultados sonoros incluso con los peores equipos. Invertir en estas situaciones también es caballo ganador.
Volumen y presión.
Cierro estos artículos sobre la psicoacústica con este sobre volumen y presión, que no es más que un resumen de todo lo contado hasta ahora. Con los tres anteriores he intentado aportar algo en el intento de mejora de nuestras mezclas. Si los recuperamos y los tenemos vivos en la memoria, nos habremos dado cuenta de que siempre terminamos en un mismo punto: nuestro cerebro. Hay dos aspectos críticos a tener en cuenta en él: la memoria acústicay la fatiga auditiva. No sólo eso, sino que ambos aspectos se ven tremendamente modificados mientras el tiempo discurre y que, para evitar sorpresas desagradables (en forma de traición), debemos “resetearlos” más a menudo de lo que hacemos.
Con las curvas de Fletcher-Munson vimos que nuestra capacidad de escucha no sólo no era lineal, sino que era distinta en función del nivel de presión sonora. En el plano horizontal nos dimos cuenta de que, utilizando la memoria acústica (de manera consciente o inconsciente), podíamos escuchar o no sonidos emitidos. Que en cada caso, un exceso o deceso de valores hacía trabajar nuestro cerebro en la búsqueda del sonido perfecto (aunque ‘perfecto’ depende del nivel cultural de cada uno de nosotros, que es otro tema).
La fatiga es nuestro peor enemigo. Hablar de volumen o de presión sonora es hablar de la capacidad del técnico de PA de conseguir que el público se canse antes o un poquito más tarde. El éxito es que el técnico tenga presente siempre ese momento, y el reto (normalmente imposible de conseguir) es que uno no llegue a un nivel de fatiga determinado donde lo único que llegas a hacer es aumentar desastrosamente el volumen.
Todo lo anterior también estoy seguro que muchos lo hemos padecido. Recordad esos momentos en que habéis sido asistentes de mesa. Empieza un concierto y al técnico de turno le dejáis un par de temas para que pula su mezcla. En el tercer tema ya tenemos la licencia para, digamos, criticar constructivamente la mezcla y, ¡qué bien!, reconocemos que está haciendo un buen trabajo. Al sexto o séptimo, ya que llevamos horas trabajando y todo funciona como debería, nos tomamos la libertad de ir a backstage o a la barra más cercana para tomar un pequeño refrigerio, ir al baño o estirar las piernas. Volvemos a control un par de temas después, y esa crítica constructiva que le habíamos otorgado se vuelve negativa de golpe y porrazo. Revisamos el nivel de volumen del equipo y nos damos cuenta que ha subido la mezcla apenas 3 o 6 dB (o una barrita más de los LEDs del máster). Miras al técnico y le preguntas si todo está ok y él te dice que sí, que perfecto… todavía esboza esa sonrisa que le regalaste justo antes de ir al bar y decirle que sonaba bien. ¿Qué está pasando? ¿Le digo que ahora suena como el culo? ¿O he sido yo que he cambiado de golpe mis estándares de audición?
Para las dos últimas preguntas la respuesta es la misma. Sí, ahora ha empezado a sonar peor y sí: tú has cambiado —mejorado— tus estándares de audición. Sin querer has realizado unreseteo acústico mental bastante más profundo de lo que esperabas: aunque hayas ido a por tu agua fresca con una oreja pendiente de la PA, en realidad has pensado en el agua, en conseguir que tus piernas te dirigieran correctamente a un lugar sorteando un numeroso público ajeno a tus necesidades, abrir la nevera, mirar a tus compañeros y saludarlos: te habrás relajado algo de todo tu proceso y, poco a poco, la parte de tu cerebro que se dedicaba a restituir sonidos ha descansado lo suficiente. No así con el técnico de PA que sigue tras la mesa: seguramente sea la persona que en ese momento más “pensaba” en el sonido, en sus elementos, en sus características. Seguía pensando y pensando obligándose a procesar cantidad de datos de manera majestual, pero cansándose cada vez más y más. Si lleva un par de cervezas encima, imagínate. Si existiera una escala de “cansancio mental”, mientras que el técnico de PA ya estaría cerca del 10 (que sería el máximo), al volver a control tu valor habría descendido hasta un 4 o 5. Esa diferencia hace que, sin duda alguna, tu escuches cosas que él ya ni puede escuchar, ni tan siquiera oir. Hace que tú puedas resolver más rápida y naturalmente decisiones que el compañero que está tocando faders no puede ni apreciar. ¿Qué debemos hacer? ¿Le decimos que suena mal? ¿Suena mal?
Desde un punto de vista objetivo, como asistentes de PA, si no existe peligro ni incidencias, no hace falta decir nada. Si queremos ayudar (que siempre está bien), podemos indicarle que, aunque no ha llegado a ningún punto crítico (seguramente estará muy cerca de él), ahora creemos que se le ha ido la pinza un poco con el nivel de volumen y que estaría bien que lo recuperase hacia la baja. Sé que es peligroso, porque muchos técnicos prefieren tener la más grande. Y al revés igual: si somos los técnicos de PA y nuestro asistente nos dice que “suena fuerte”, deberíamos recordar estas líneas y darle la razón.
El técnico de PA debería tener en cuenta estas propiedades psicoacústicas e intentar no llegar a este punto. Servidor, consciente de ello, no sólo intenta mantener la cabeza fría en cada momento (algo que a veces consigo, pero muchas otras no) y buscar que los sonidos se propaguen como quiero, sino que, instintivamente, cada dos o tres temas bajo los niveles de volumen, ni que sea un poquito y aunque crea que no es necesario. Es simplemente un truco, no una norma ni aún menos un proceso magistral.
Un pequeño inciso. No todos los grupos arrastran tanta gente como para que el control de sonido realmente esté en medio de platea. Aunque físicamente esté ahí, como técnico de grupo tienes que ser coherente y saber ver que esa noche la gente que realmente quiere escuchar el concierto apenas ocupa el espacio que hay entre el escenario y control (los que están más allá, si quieren ya se moverán). De hecho, la gran mayoría de veces sonorizarás una banda siendo el “último” del público, el último de la fila: si a control ya está fuerte, ¿cómo lo estará ahí delante?
Las herramientas de medición que hoy tenemos a nuestro alcance nos deberían ayudar a resolver este gran problema. Si a los dos o tres temas de empezar estamos contentos con lo que tenemos, basta con fijar un límite basado en puntos objetivos, como el nivel de presión sonora medido a control, a la par que observamos la respuesta del RTA o del espectrograma. Ellos no nos fallarán. Si ese es nuestro punto de referencia vale la pena mantenerlo, aunque a medio plazo creamos que “podríamos subir más el volumen”. Si aparece esta pregunta en un momento de nuestra mezcla, antes deberíamos dudar de esa necesidad y pensar si realmente lo que nos ocurre es que estamos “cansados”, fatigados. No sólo se sube el volumen moviendo físicamente un fader: la compresión afecta de la misma manera.
Subimos el nivel de volumen a medio repertorio porque creemos que tenemos una necesidad de buscar nuevos sonidos que nos den espectacularidad. Esa necesidad, en realidad, es un efecto (de hecho defecto) de una escucha a niveles altos de presión, donde nuestro sistema auditivo (junto con el proceso cerebral) se protege “comprimiendo” lo que escuchamos. Esta posibilidad de escuchar bien sonidos altos en volumen implica, negativamente, la pérdida de una escucha dinámica. Por eso, instintivamente queremos subir el nivel de volumen, ya que en cierto modo al “comprimir” la escucha hemos subido el nivel de suelo o threshold inferior (pensad en el símil, claro está). Pensamos que al subir, tendremos más dinámica. Y no es así, sino justo lo contrario: al subir más, nos protegeremos más, comprimiremos “mentalmente” más lo que escuchamos. Recordad qué sucede cuando a altos niveles de presión recibimos una ingente cantidad de energía de las altas frecuencias. Y si a todo esto le añadimos el procesado (también de compresión) que realiza nuestro equipo al acercarnos al límite establecido, obtendremos un sonido comprimido, inútil en dinámica y desequilibrado a más no querer.
Ante estas situaciones, entonces, lo único que podemos hacer es ir hacia abajo, hacer justamente lo contrario de lo que pensamos. De manera instintiva, al bajar el volumen, nuestro sistema de protección auditiva se relajará, dejará de comprimir y recuperará una dinámica de escucha mucho mejor. Por eso, las mejores mezclas se consiguen a niveles de presión sonora bajas pero también por eso nos es difícil distinguir si el nivel de presión sonora es el mismo en este caso o cuando está sonando Manowar (el grupo que ostenta el record Guiness de mayor presión sonora en un concierto). Las máquinas dirán que no, que en realidad es una presión muy diferente; pero nuestro cerebro agradecerá el primero de los casos, se fatigará menos y cuando volvamos a control con nuestra agua fresca seremos los primeros en reconocer que sí, que esa mezcla sonaba muy muy bien. Una verdadera lástima ver que una gran mayoría de técnicos prefieran el rojo al placentero verde con picos naranjas.
Artículos publicados en www.hispasonic.com